A new idea of ​​neural network for artificial intelligence: linear nonlinear problem with OpenAI
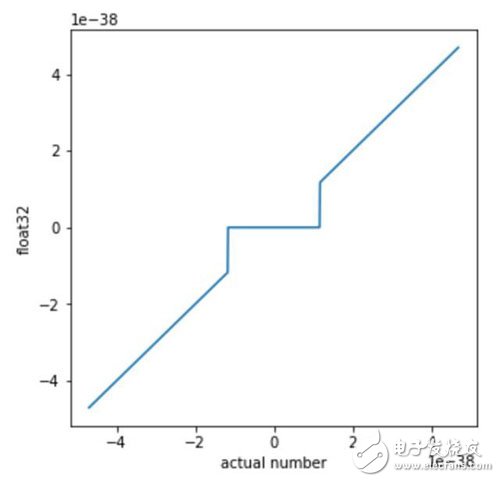
Neural networks are usually made up of a linear layer and non-linear functions such as tanh and modified linear unit ReLU. If there is no nonlinearity, theoretically a series of linear layers and a single linear layer are mathematically equivalent. Therefore floating point operations are non-linear and sufficient to train deep networks. This is very surprising. The numbers used by computers are not perfect mathematical objects, but rather approximate representations of a finite number of bits. Floating point numbers are often used by computers to represent mathematical objects. Each floating point number consists of a combination of fractions and exponents. In the IEEE float32 standard, the decimal is allocated 23 bits, the exponent is allocated 8 bits, and the other bit is the sign bit sign indicating positive and negative. According to this convention and binary format, the minimum non-zero normal number expressed in binary is 1.0..0 x 2^-126, which is referred to below by min. The next representable number is 1.0..01 x 2^-126, which can be written as min+0.0..01 x 2^-126. Obviously, the gap between the first and second numbers is 2^20 times smaller than the gap between 0 and min. In the float32 standard, when a number is smaller than the smallest representable number, the number will be mapped to zero. Therefore, all calculations involving neighbors with zeros will be non-linear. (There are exceptions to the inverse constants, which may not be available on some computing hardware. In our case, this problem is solved by setting flush to zero (FTZ), which treats all inverse constants as zero.) Therefore, although the difference between all numbers and their floating-point representations is usually small, a large gap occurs near zero, and this approximation error can have a large effect. This can lead to some strange effects, and some common mathematical rules don't work. For example, (a + b) xc is not equal to axc + bxc. For example, if you set a = 0.4 x min, b = 0.5 x min, c = 1 / min. Then: (a+b) xc = (0.4 x min + 0.5 x min) x 1 / min = (0 + 0) x 1 / min = 0. However: (axc) + (bxc) = 0.4 x min / min + 0.5 x min x 1 / min = 0.9. For another example, we can set a = 2.5 x min, b = -1.6 x min, and c = 1 x min. Then: (a+b) + c = (0) + 1 x min = min However: (b+c) + a = (0 x min) + 2.5 x min = 2.5 x min. In this small scale case, the underlying addition becomes non-linear! We want to know if this intrinsic nonlinearity can be used as a method for calculating nonlinearity. If possible, a deep linear network can perform nonlinear operations. The challenge is that modern differential libraries ignore them when the nonlinear scale is small. Therefore, it is difficult or impossible to train a neural network using nonlinear propagation using backpropagation. We can use the evolutionary strategy (ES) to evaluate the gradient without relying on the symbolic difference enTIaTIon method. Using evolutionary strategies, we can use float32's near-zero behavior as a way to calculate nonlinearity. When the deep linear network is trained on the MNIST dataset by backpropagation, it can obtain 94% training accuracy and 92% test accuracy (the machine heart can achieve 98.51% test accuracy using the three-layer fully connected network). In contrast, the same linear network uses evolutionary strategy training to achieve greater than 99% training accuracy and 96.7% test accuracy, ensuring that the activation values ​​are small enough to be distributed over the nonlinear range of float32. The reason for the improvement in training performance is the use of nonlinear evolutionary strategies in the float32 representation. These powerful nonlinearities allow arbitrary layers to generate new features that are nonlinear combinations of low-level features. The following is the network structure: In the above code, we can see that the network has a total of 4 layers, the first layer is 784 (28 * 28) input neurons, this number must be the same as the number of pixels contained in a single picture in the MNIST data set. Both the second and third layers are hidden layers with 512 neurons per layer and the last layer is the 10 classification categories of the output. The full connection weight between each two layers is a random initialization value that obeys a normal distribution. Nr_params is the cumulative multiplication of all parameters. The following defines a get_logist() function whose input variable par should be the nr_params defined above, because the index that defines the addition of the offset is 1, 3, 5, which coincides with the previously defined nr_params, but OpenAI does not. Give the calling procedure of the function. The first expression of the function calculates the forward propagation result between the first layer and the second layer, that is, calculates the product between the input x and w1 plus the scaled offset term (both b1, b2, and b3) Define a zero vector). The calculations in the next two steps are basically similar, and the last returned o should be the category of picture recognition. However, OpenAI only gives the network architecture, but does not give the optimization method and loss function. 2.1 Home Theater Speaker,2.1 Speaker System Home Theater,Surround Sound Speakers,2.1 Home Theater GUANGZHOU SOWANGNY ELECTRONIC CO.,LTD , https://www.jerry-power.com