MRAN-based nvNITRO NVMe storage accelerator card for 1.46 million I/O speeds
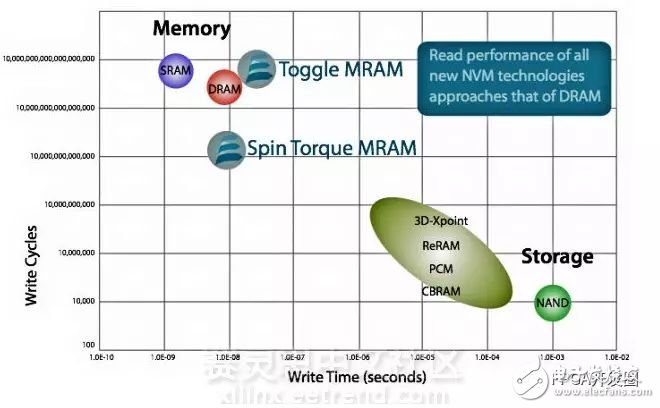
With the increase of the processing speed of major processors, especially in the competitive environment of CPU and operating speed in the past few years, the development of the entire CPU speed is basically in accordance with Moore's Law, but in the past ten years, the speed of the CPU has changed. It is very slow. I personally think that there are two main reasons. One is the process, the Other is the memory access, and the data is placed in the access area. It is difficult to load into the core quickly. Also in the major design applications, the memory IO speed problem has become more and more prominent, so to date, has there been some breakthrough in the IO speed on the memory access? Everspin's nvNITRO NVMe card Last month, Everspin announced their latest development of the MRN-based nvNITRO NVMe storage accelerator card. The eye-catching feature is that they give the accelerator card IO access speed: for a random mix of 4KB 70/30 The IO speed of the read and write operation can reach 1.46 million. This speed is a bit of a bit of a surprise, but this speed should be the fastest in the current IOPS world. In other words, this IOPS speed has almost tripled that of Intel's P4800X Optane SSD card (Optane's IOPS can reach 500K at random 4KB 70/30 read and write operations). The reason is that there are many factors that contribute to such a high IOPS rate. First, this nvNITRO storage accelerator card uses Everspin's latest high-speed 1Gb ST-MRAM (Spin Torque Magnetostrictive RAM), DDR4, SDRAM compatibility IO; secondly, acceleration The card is internally configured with NVMe 1.1+ compatible MRAM dedicated storage control IP blocks; the key is to use the Xilinx Kintex UltraScale KU060 FPGA chip to implement the MRAM controller to PCIe Gen3X8 host interface for the entire board, which is IO The high-speed access laid the foundation. At the same time, it is worth noting that Everspin's nvNITRO NVMe card will be seen on Q4 2017, and its usable capacity will reach 1 or 2GB, which is worth looking forward to. Figure 1: Everspin's nvNITRO NVMe card Unlike the storage technologies that were implemented in the past when implementing NVMe cards, non-volatile MRAMs have achieved some significant advantages, such as its non-volatile nature, which eliminates the need for backup power. In addition, ST-MRAM has a very high endurance, so the nvNITRO card can perform write operations without restrictions every day without error, which saves the NAND Flash storage to be used to store some stealth through the wear leveling algorithm. The need for cycle, at the same time, with the increase of running time, the read and write performance has not been reduced. Figure: Everspin ST-MRAM fast write and high write endurance From the above coordinate system, as the Y-axis data increases, it can be seen that the write speed of Everspin's ST-MRAM is quite fast on the X-axis, almost the same as the DRAM speed. Of course, this is indeed the realization of the nvNITRO accelerator. One of the reasons for the relatively fast read and write rates. In addition, one of the points in the data sheet for the Everspin nvNITRO NVMs storage accelerator is that "users can customize the feature by writing their own RTL code to the programmable FPGA chip" (original: Customer-defined features using own RTL with programmable FPGA) ), this is like the user can write code in the Lintex UltraScale KU060 FPGA chip in the nvNITRO storage accelerator card system to implement PCIe interface and ST-MRAM controller, that is, you can write yourself without increasing BOM overhead. The unique requirements code is in this design system. If you say this, if you have such a board around you, it is worth a try. to sum up In the whole introduction above, it is mainly to highlight the speed of the nvNITRO accelerator card access speed, and analyze the reasons for its fast. In fact, combined with some previous articles, we can find and summarize a key point: the use of FPGA is actually a prerequisite for achieving these performances, for example, the application FPGA can flexibly implement various data interfaces and controllers; The flexibility of the entire system is completely different, and more space is left for the user's own design. I believe that in the future, more Xilinx high-performance FPGA design will pay more attention to the flexibility of FPGA. Motorola Portable Radio,Portable Two Way Radio,Motorola Vhf Handheld Radio,Multi Band Portable Radio Guangzhou Etmy Technology Co., Ltd. , https://www.digitaltalkie.com