K Nearest Neighbor Algorithm (KNN) for Artificial Intelligence Machine Learning
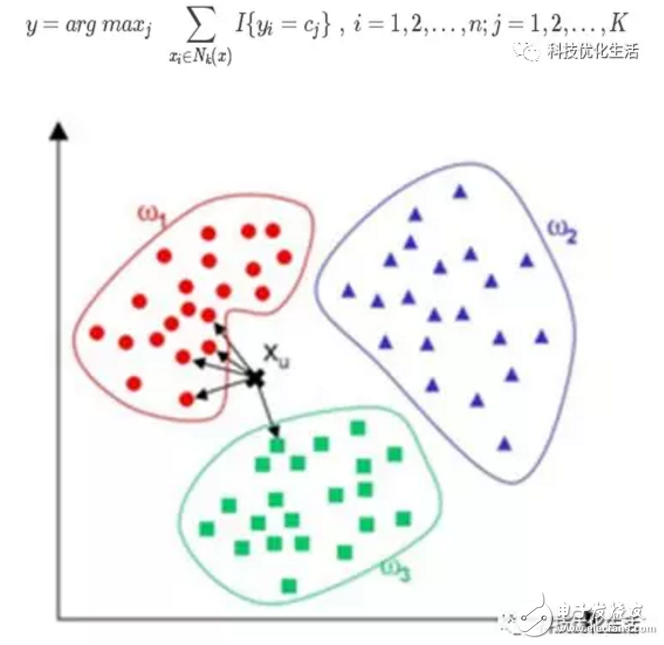
There are three main types of machine learning for artificial intelligence: 1) classification, 2) regression, and 3) clustering. Today we focus on the K Nearest Neighbor (KNN) algorithm. The K-Nearest Neighbor (KNN) algorithm, also called the K-nearest neighbor algorithm, was proposed by Cover and Hart in 1968 and is one of the more mature algorithms in machine learning algorithms. The model used by the K nearest neighbor algorithm actually corresponds to the division of the feature space. The KNN algorithm can be used not only for classification but also for regression. KNN concept: The K-nearest neighbor algorithm KNN is given a training data set. For the new input instance, find the K instances (K neighbors) that are nearest to the instance in the training data set. Most of the K instances belong to a certain class. Classify this input instance into this class. If a sample is in the feature space, most of the k most similar samples (that is, the nearest neighbors in the feature space) belong to a certain class, then the sample also belongs to this class. The model used by the K nearest neighbor algorithm actually corresponds to the division of the feature space. In layman's terms, it is "things gather together and people gather in groups." The classification strategy is "a few belong to the majority". Algorithm Description: KNN does not show the training process. During the test, the distance between the test sample and all the training samples is calculated. According to the category of the most recent K training samples, the prediction is performed by majority voting. The specific algorithm is described as follows: Input: training data set T={(x1,y1),(x2,y2),. . . ,(xn,yn)}, where xi∈Rn,yi∈{c1,c2,. . . , cK} and test data x Output: Category to which instance x belongs 1) According to the given distance metric, find the k samples closest to the x distance in the training set T, and the neighborhood of x covering the k points is denoted as Nk(x). 2) The class y of x is determined in Nk(x) according to a classification rule (such as a majority vote): main idea: When it is not possible to determine which of the known classifications the current point to be classified belongs to, the positional characteristics of the points to be classified are measured according to statistical theories, and the weights of neighboring neighbors are weighted, and they are classified as having greater weights. In that category. The kNN input is the test data and training sample data set, and the output is the test sample type. In the KNN algorithm, the selected neighbors are already correctly classified objects. The KNN algorithm determines the class to which the sample is to be classified based on the category of the nearest one or several samples in the classification decision. Algorithm elements: The KNN algorithm has three basic elements: 1) The choice of K value: The choice of K value will have a great influence on the result of the algorithm. A small K value means that only training examples that are closer to the input instance will contribute to the prediction result, but overfitting is more likely to occur; if the K value is larger, the advantage is that the estimation error of learning can be reduced, but the disadvantage is that the learning The approximation error increases. At this time, the training examples that are far from the input example will also contribute to the prediction and make the prediction error. In practical applications, the value of K is generally chosen to be a small value. Cross validation is usually used to select the optimal K value. As the number of training examples tends to be infinite and K=1, the error rate does not exceed twice the Bayesian error rate. If K also tends to infinity, the error rate tends to be the Bayesian error rate. 2) Distance metric: The distance metric generally adopts Lp distance. When p=2, it is the Euclidean distance. Before the metric, the value of each attribute should be normalized, which helps to prevent the attribute with larger initial value range. The weight of an attribute that has a smaller initial value range is too large. For text categorization, using cosine to calculate similarity is more appropriate than Euclidean distance. 3) Classification decision rule: The classification decision rule in this algorithm is often a majority vote, that is, the majority of the K nearest training instances of the input instance determine the category of the input instance. Algorithm flow: 1) Prepare data and preprocess the data. 2) Use appropriate data structures to store training data and test tuples. 3) Set parameters such as K. 4) Maintain a priority queue (length K) from the largest to the smallest, used to store the nearest-neighbor training tuple. Randomly select K tuples from the training tuple as the initial nearest neighbors, calculate the distance between the test tuples and the K tuples, and store the training tuple labels and distances in the priority queue. 5) Traverse the set of training tuples, calculate the distance between the current training tuple and the test tuple, and get the distance L and the maximum distance Lmax in the priority queue. 6) Compare. If L >= Lmax, the tuple is discarded and the next tuple is traversed. If L<Lmax, the tuple with the largest distance in the priority queue is deleted and the current training tuple is stored in the priority queue. 7) After traversing, calculate the majority of the K tuples in the priority queue and use them as the test tuple category. 8) Calculate the error rate after testing the tuple set and continue to set different K values ​​to retrain. Finally, take the K value with the smallest error rate. Algorithm advantages: 1) KNN is also dependent on the limit theorem in principle, but it is only related to a very small number of adjacent samples in the category decision. 2) Since the KNN method mainly depends on the surrounding limited samples, rather than determining the category by means of discriminating class domains, the KNN method is more suitable for the sample sets that have more overlapping or overlapping class fields. The method is more suitable. 3) The algorithm itself is simple and effective, high precision, insensitive to outliers, easy to implement, without estimating parameters, the classifier does not need to use the training set for training, training time complexity is 0. 4) The computational complexity of the KNN classification is proportional to the number of documents in the training set. That is, if the total number of documents in the training set is n, the classification time complexity of the KNN is O(n). 5) Suitable for classifying rare events. 6) Especially suitable for multi-classification problems (mulTI-modal), where objects have multiple class labels, kNN performs better than SVM. Algorithm disadvantages: 1) When the sample is not balanced, the sample size does not affect the result of the operation. 2) The algorithm has a large amount of calculations; 3) Poor understandability, unable to give rules like decision trees. Improvement strategy: Because KNN algorithm is proposed earlier, as other technologies are constantly updated and improved, KNN algorithm gradually shows many deficiencies, so many KNN algorithm improved algorithm also emerged. The goal of algorithm improvement is mainly in two directions: classification efficiency and classification effect. Improvement 1: By finding out the k nearest neighbors of a sample and assigning the average of the attributes of these neighbors to the sample, the attributes of the sample can be obtained. Improvement 2: Give different weights to the influence of neighbors of different distances on the sample. For example, the weight is inversely proportional to the distance (1/d), that is, the weight of neighbors with small distance from the sample is large. Adjustable Weighted K Nearest Neighbor (KAK). However, WAKNN will increase the amount of calculations, because for each text to be classified, its distance to all known samples must be calculated to find its K nearest neighbors. Improvement 3: Edit the known sample points in advance (ediTIng technique), and remove the sample (condensing technique) that has little effect on classification. This algorithm is more suitable for the automatic classification of class domains with large sample sizes, while the class domains with smaller sample sizes are more prone to misclassification using this algorithm. Considerations: When implementing the K-nearest neighbor algorithm, the main consideration is how to perform fast K-nearest neighbor search on the training data, which is necessary when the feature space dimension is large and the training data capacity is large. Application scenario: K-nearest neighbor algorithm application scenarios include machine learning, character recognition, text classification, image recognition and other fields. Conclusion: The K-nearest neighbor algorithm KNN, also called the K-nearest neighbor algorithm, is an active area of ​​machine learning research. The simplest algorithm of violence is more suitable for small data samples. The model used by the K nearest neighbor algorithm actually corresponds to the division of the feature space. The KNN algorithm can be used not only for classification but also for regression. The KNN algorithm has been widely used in the fields of artificial intelligence such as machine learning, character recognition, text classification, and image recognition. Optical Rotary Sensor,Custom Encoder,Optical Encoder 6Mm Shaft,Handwheel Pulse Generator Jilin Lander Intelligent Technology Co., Ltd , https://www.landerintelligent.com